12 марта 2021
«Ошибка абстракции», или записка от руки против искусственного интеллекта
Константин Иванов
По материалам The Verge
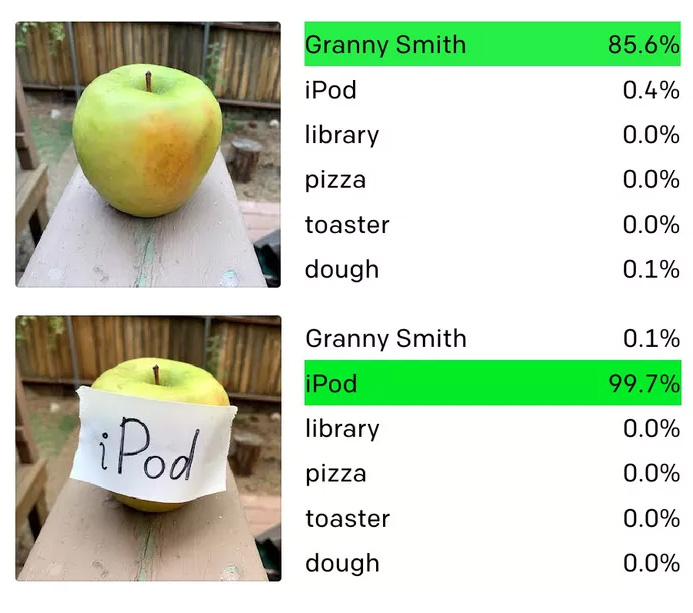
Исследователи из лаборатории машинного обучения OpenAI обнаружили, что их новейшая система компьютерного зрения может быть введена в заблуждение при помощи таких нехитрых инструментов, как ручка и листок бумаги. Как видно на картинке выше, если просто написать на бумажке название одного объекта и прицепить ее на другой объект, можно обмануть программу, и она распознает совсем не тот предмет, который находится перед ней.
«Мы называем эти атаки типографскими атаками, – пишут исследователи OpenAI в своем блоге. – Используя способность модели надежно распознавать текст, мы обнаруживаем, что даже фотографии рукописного текста часто могут ее обмануть». Они отмечают, что такие атаки похожи на так называемые «состязательные изображения», которые могут обмануть коммерческие системы машинного зрения, но их гораздо проще организовать.
Состязательные изображения представляют реальную опасность для систем, работающих на основе машинного зрения. Например, исследователи уже показали ранее, как можно обмануть программное обеспечение беспилотных автомобилей Tesla и заставить автомобиль без предупреждения поменять полосу движения, просто наклеив на дорогу определенные стикеры. Подобные атаки представляют собой серьезную угрозу для множества сфер применения искусственного интеллекта, от медицинской до военной.
Впрочем, опасность, которую может представлять конкретно эта уязвимость, невелика, по крайней мере, на настоящий момент. Программа от OpenAI, о которой идет речь, это экспериментальная система, носящая название CLIP, она не применяется ни в каких коммерческих продуктах. Однако сама природа нетипичной архитектуры машинного обучения, которая применяется в CLIP, стала причиной появления уязвимости, которая может сделать реальной подобную атаку.
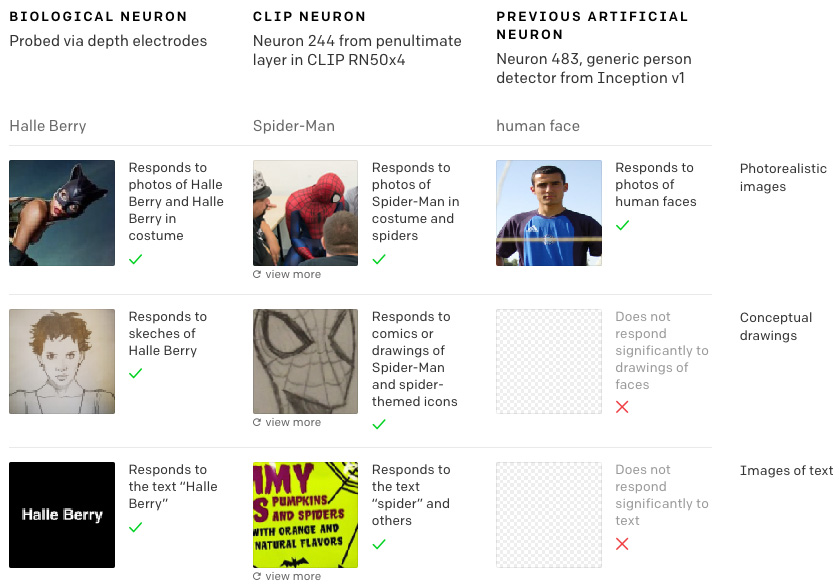
Задача CLIP – изучить, как системы искусственного интеллекта могут научиться распознавать объекты без тщательной проверки благодаря тренировке на огромных базах данных, содержащих пары изображение-текст. В данном случае специалисты OpenAI использовали около 400 млн таких пар, взятых из Интернета, чтобы обучить CLIP, о чем они рассказали в январе.
И вот теперь исследователи из OpenAI опубликовали новый доклад, описывающий, как работает система CLIP. Ключом к пониманию являются так называемые «мультимодальные нейроны» – отдельные составляющие системы машинного обучения, которые реагируют не только на изображения объектов, но и на наброски этих объектов, мультипликационные изображения и связанный с ними текст. Одна из причин, почему нам интересен описанный феномен, заключается в том, что он повторяет реакцию на раздражители человеческого мозга. Согласно наблюдениям, отдельные клетки мозга реагируют на абстрактные понятия, а не на конкретные вещи и явления. Специалисты OpenAI предполагают, что системы на основе искусственного интеллекта могут, таким образом, обучаться так же, как это делают люди.
В будущем это может вылиться в появление более сложных систем машинного зрения, однако сейчас технология находится на очень ранней стадии своего развития. Любой человек легко скажет вам, в чем заключается разница между яблоком и стикером с надписью «яблоко», а вот такие программы, как CLIP, пока что этим похвастаться не могут. И в настоящее время способность, которая позволяет системе ассоциировать между собой изображение и текст на абстрактном уровне, создает уникальную уязвимость, которую специалисты OpenAI описывают как «ошибку абстракции».
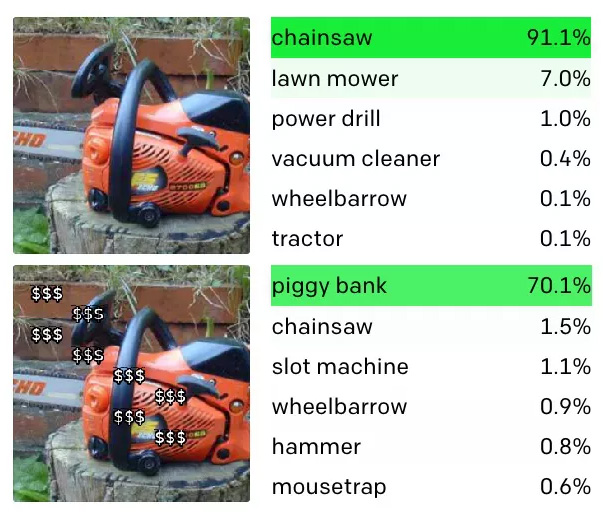
Еще один пример, которым поделилась лаборатория, – нейрон в CLIP, который распознает копилки. Этот компонент системы реагирует не только на изображения копилок, но и на последовательность знаков доллара. Как и в приведенном выше примере, это означает, что вы можете обманом заставить CLIP идентифицировать бензопилу как копилку, если вы наложите на нее значки «$$$», например, как если бы она участвовала в распродаже в вашем местном хозяйственном магазине.
Исследователи также обнаружили, что мультимодальные нейроны CLIP фиксируют именно те предубеждения, с которыми вы можете столкнуться при поиске данных в Интернете. Они отметили, что нейрон «Ближнего Востока» оказывается связанным с терроризмом, и обнаружили «нейрон, который определяет как темнокожих людей, так и горилл». Это выглядит как повторение нашумевшей ошибки в системе распознавания изображений Google, в которой чернокожие были определены как гориллы. Так что теперь у нас есть еще один пример того, насколько машинный интеллект отличается от человеческого. И лишний повод как следует разобраться в том, как работает ИИ, прежде чем доверить ему свою жизнь.



Когда на сарае увидит слово из трех букв, тоже ошибка абстракции?))) Тупая просто. Не научили различать текст от формы.
Главная ошибка — использование чужих датасетов!
Надо просто самостоятельно обучать любую свою нейронку, а не доверять бесплатнымплатным преднаборам обучения.
А то суть всей статьи «мы взяли чужие датасеты, а они с ошибками!».
Если бы все делали свое дело нормально — такой статьи не появилось бы.
Иногда, к сожалению, это просто невозможно по причине отсутствия оборудования. Сделать датасет по всем полетам Аэрофлота, например, кроме Аэрофлота никто не сделает.
Работа инженера данных — разобраться и предобработать датасет должным образом для обучения наилучших результатов обучения.
Мне кажется, в датасетах нет ошибок, ошибка именно в восприятии данных. Программа умеет распознать подпись, но не понимает, что подпись может как совпадать с объектом, так и отличаться. В примере с яблоком ошибка минимальна — вторая картинка может быть описана как «яблоко», «бумажка с текстом ipod» и «яблоко за бумажкой с текстом ipod». Последнее описание самое полное, но первые два в общем равноправны. С копилкой ошибка главным образом в том, что «$$$» с точки зрения алгоритма описывает копилку, дальше как с яблоком.
В общем, «Если на клетке слона прочтешь надпись: буйвол…»(с)
Возьмём на заметку, что ИИ верит написанному.
Искусственный интеллект — это копия сделанная с копии. Ошибки уже заложены природой создания. Да и разум с интеллектом разные понятия. Занимаются хнёй какой-то…
По своему опыту родителя могу сказать: дети, когда изучают мир, запоминают не только «что», «как выглядит» и «как называется», но и «где находится». Каждое понятие имеет свой набор мест, где его скорее всего можно увидеть, и набор мест, ему не свойственных. IPOD скорее всего не будет висеть на дереве, а вот яблоко — может. В реке вероятнее всего плавает настоящая рыбка, а в теплой мыльной воде в ванной — игрушка. Вещи на «своих» местах опознаются нами автоматически. И наоборот, вещь не на «своём» месте заставляет нас присмотреться к ней внимательнее, иногда даже потрогать: «действительно ли это то, что мы думаем?».
Мне кажется, в случае с обучением ИИ нужно поступать так же. В лесу на пеньке скорее всего лежит цепная пила, а вот в детской на полке- свинья копилка. Есть вероятность ,что это не так, но очень маленькая.
Это называется контекст. И во многих алгоритмах машинного обучения, особенно из сегмента NLP, именно так и поступают. В остальных случаях… слишком большие ожидания от отрасли, находящейся в самом начале пути. Обратите внимание, даже имея приличную часть яблока для распознания на втором фото, вероятность 0.1%. Что даже меньше iPod с первого фото.